 By Rakesh Patel
By Rakesh Patel
“Advancements in the image recognition fields are propelling the computer vision capabilities forward.”
The image recognition models are constantly rising. It can be easily evident from the statistical data presented by MarketsandMarkets. It states that the market size for image recognition is anticipated to expand from $26.2 billion in 2020 to $53.0 billion in 2025, at a CAGR of 15.1%.
With this rising exponential growth in the digital world, there is an increasing need for sophisticated image recognition technology. OpenAI, the research laboratory in artificial intelligence, has been at the forefront of developing edge-cutting image recognition models.
Let’s dive into OpenAI’s contribution to image recognition, different techniques used in image recognition, and their applications across various industries.
Table of Content
- What is Image Recognition?
- OpenAI’s ChatGPT Achieves Remarkable Breakthroughs in Image Recognition
- Practical Applications of Image Recognition
- The Emergence of OpenAI’s Image Recognition Models
- Let’s Know More About CLIP – Powered By OpenAI
- Features of CLIP
- Implementation of CLIP
- CLIP Architectures
- Different techniques to boost image recognition
- OpenAI’s Contributions in Enhancing Image Recognition Capabilities through GANs
- FAQs
- Conclusion
What is Image Recognition?
Image recognition is an AI-powered technology that boosts computer vision capabilities. Image recognition is the technological ability to recognize objects, people, and other visual components in digital images and videos. Their machine-learning algorithms are trained on massive datasets of images. This ensures their capability to automatically recognize the patterns and features in images without any human interventions.
The overall goal of image recognition is to allow machines to comprehend and interpret the visual world based on their training data in a manner similar to that of humans.
OpenAI’s ChatGPT Achieves Remarkable Breakthroughs in Image Recognition
OpenAI’s ChatGPT has recently rolled out image and voice enhancement capabilities. ChatGPT was traditionally a text-based AI model that could understand and generate text-based responses only.
However, as per the recent notification by OpenAI on Twitter, it can now easily process and respond to visual and auditory inputs in addition to text. This means it can analyze images and understand spoken language, making it a more versatile and human-like conversational AI.
Here is a video for your reference:
Practical Applications of Image Recognition
Image recognition is on its way to being a blessing for various industries. Learn which industries are practically getting benefitted from image recognition technology.
- Security:
Be it corporate offices, airports, residential buildings, or government offices, image recognition is widely used for safety purposes. Because of its facial recognition capability, and object detection power, potential threats can be reduced.
- Automotive:
Automation is everywhere. Now, self-driven cars are the new area of focus. The image recognition capabilities are pushing this trend forward. Image recognition helps self-driving cars to identify objects on the roads such as vehicles, pedestrians, and traffic signs, navigate the roads and make self-driven cars more autonomous and reliable.
Image recognition can also be used to track the behavior of the driver and warn them of possible dangers or distractions. For instance, cameras can be used to spot indications of driver fatigue or when the driver isn’t paying attention to the road and alert the driver or take appropriate corrective action.
- Healthcare:
Medical imaging and diagnosis are two areas where image recognition is especially useful in the healthcare sector. Medical imaging methods like X-rays, CT scans, and MRI scans generate a lot of data that can be challenging for doctors to correctly interpret and analyze.
By spotting patterns and anomalies in medical pictures and pointing out potential problem areas, image recognition algorithms can aid in automating this process.
For instance, it can be used to recognize tumors, spot bone fractures, or find indications of heart illness or other conditions.
- Manufacturing:
Image recognition has become a vital instrument in the manufacturing sector for enhancing quality control and guaranteeing that goods adhere to strict quality standards. Image recognition algorithms can find flaws and inconsistencies in products that might not be obvious to the unaided eye by examining images of products at different phases of the manufacturing process.
For instance, image identification can be used to spot product flaws like scratches, dents, or misaligned components. The ability to quickly and accurately identify these flaws enables manufacturers to make necessary corrections before the goods leave the factory and reach customers.
The Emergence of OpenAI’s Image Recognition Models
Because of the growing need for sophisticated computer vision technology across many sectors, there is a constant need to improve or create new image recognition models. Additionally, there is a need for models that can handle new types of data and carry out more difficult jobs as technology develops and new use cases appear.
This is the time when OpenAI’s contribution to image recognition comes in. OpenAI has been creating and enhancing advanced models to handle the shortcomings of the existing ones. Their research has produced innovations in self- and unsupervised learning that have shown promise in raising the precision and effectiveness of image identification models.
A few of the models by OpenAI are mentioned here:
- DALL-E:
The way GPT proved that a large language model also referred to as a neural network can be programmed to carry out a variety of text generation activities using language, similarly, the Image GPT concept by OpenAI proved that the same neural network can be used to generate images.
DALL-E is a state-of-the-art image generation model created by OpenAI that has revolutionized the field of AI-generated images. The model can generate images from written descriptions, which can include anything from short phrases to lengthy sentences. It is trained on 12 billion parameters. It is capable of receiving both texts as well as images as a single stream of data containing up to 1280 tokens.

Source: Image generation – OpenAI API
For a wide range of sentences that explore language structure, DALL-E can produce images that are realistic. The model’s capabilities are demonstrated through a series of interactive visuals, where the top 32 images for each caption are shown without any manual selection.- CLIP:
Another significant contribution made by OpenAI to boost image recognition tactics is CLIP. It stands for Contrastive Language Image Pre-training. CLIP (Contrastive Language-Image Pre-Training) is one of the large language models that was invented by OpenAI. The main purpose behind the launch of CLIP is to tackle the challenges that involve image and natural language recognition. It is taught to associate visual and textual patterns in order to anticipate the relationship between images and their associated text descriptions.
Basically, the version of CLIP we use here consists of two models, a text transformer and a vision transformer. These two CLIP models are for encoding text and image embeddings. Both CLIP models are optimized during pretraining to align similar text and images in vector space. This practice enables CLIP to perform a wide range of tasks such as image classification, object detection, and even generating images from natural language descriptions.Let’s Know More About CLIP – Powered By OpenAI
CLIP (Contrastive Language-Image Pre-training) is an entire deep learning approach that aims to create a joint embedding space between natural language and visual representations, allowing for cross-modal reasoning. This approach is achieved through pre-training a neural network called CLIP, on a large amount of image-text pairs, where the network learns to associate the visual features of an image with corresponding textual ones.
The pre-training is done in a contrastive manner, where the network learns to distinguish between correct image-text pairs and incorrect ones. Once pre-trained, the CLIP model can be fine-tuned on various downstream tasks, such as image classification or visual question answering, without the need for additional labeled data. This is made possible by the zero-shot capabilities of CLIP, which allows it to generalize to new tasks with only a few examples or even without any labeled data for the specific task at hand.
Features of CLIP
There are certain unique characteristics of the CLIP model which are described below:
- Multimodal learning: CLIP learns from both text and image inputs simultaneously, enabling it to comprehend the relationship between them.
- Generalization: CLIP is a flexible model that can generalize to a variety of activities outside of its pre-training goals.
- Zero-shot learning: CLIP can perform zero-shot image classification by recognizing things and ideas that it has never seen before.
- Pre-training on a large scale: CLIP is trained on a huge dataset of more than 400 million image-text pairs. On the contrary just for the sake of comparison, ImageNet datasets contain 1.2 million changes.
Implementation of CLIP
An example of the CLIP model is stated here:
In the first step, the image is to be taken: Here the image has been taken from Unsplash and the photo credit goes to Olivia Hibbins.

In the second step, we need to provide CLIP, the following prompts:
- a girl with a yellow flower in hand
- a girl with a flower
- a boy with a Yellow flower
- a dog
Here by looking at the image and the text description, it is seen that the first description better suits the image.
By allocating a normalized probability to each text prompt, CLIP automatically determines which one best describes the picture. Have a look:
“a girl with a yellow flower in hand a girl with a flower a boy with a Yellow flower a dog“

CLIP Architectures
CLIP is a deep learning model that gets inspired by the novel ideas of existing architectures like Zero and introduces some of its own. Here one of those ideas is discussed:
Contrastive Pre-training Architecture
Here, figure 1 shows an overview of the Contrastive Pre-training process. Let’s understand:
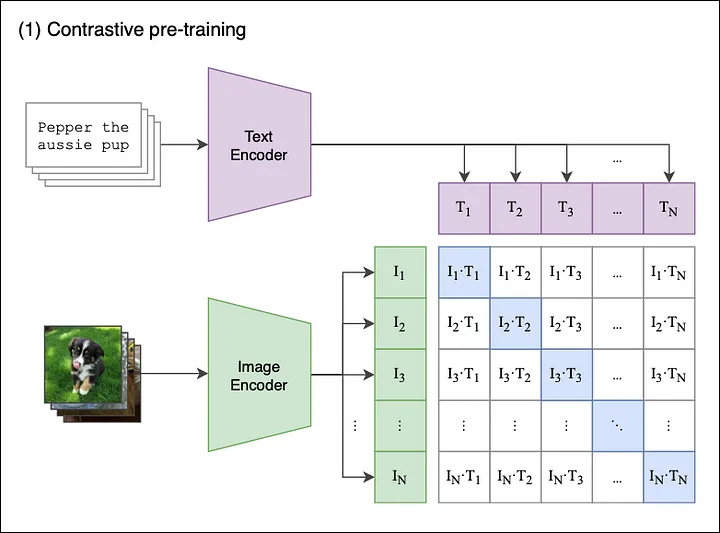
Assume, we have a batch of ‘n’ images paired with their text descriptions such as <image1, text1>, <image2, text2>, <imageN, textN>
The goal of Contrastive pre-training is to jointly train an image and a text encoder that creates image embeddings [I1, I2… IN] and text embeddings [T1, T2… TN], in a manner that:
- The cosine similarities between the matching image and text embedding pair should be maximized, where i=j.
- The cosine similarity between the two incorrect image and text embedding pairs should be minimized, where i≠j.
Let’s understand how the contrastive pre-training process is followed step-by-step:
- The model receives a group of N pairs of images and text <image-text>.
- The Image Encoder could either be among the ResNet versions that may include ResNet 18, ResNet 34, ResNet 50, or ResNet 101, etc. , while the Text Encoder is a Transformer model.
- For each image in the batch, the image encoder produces an image vector (I1,I2, In ……) which forms an N X de matrix.
- The textual descriptions are transformed into text embeddings (T1,, T2, Tn……) which form another N X de matrix.
- The two matrices are multiplied, and the pairwise cosine similarities between every image and text description are calculated. This results in an N X N matrix.
- The aim is to maximize the cosine similarity of the correct <image-text> pairs on the diagonal and to minimize the off-diagonal cosine similarity for the incorrect pairs.
Different techniques to boost image recognition
There are a few techniques to be used to boost the image recognition models. Have a look:
- Supervised learning: Under the supervised learning method, the model is trained with a labeled dataset. In supervised learning, input images and their associated labels are given to the model. The model then acquires the ability to identify data trends and link them to the labels.
- Unsupervised learning: Here the model is trained on an unlabeled dataset. The model is not provided or trained with any labels. They have to identify the pattern of the data on their own.
- Transfer learning: Transfer learning is a technique that involves using a pre-trained model as a starting point for a new task. The pre-trained model has already learned to recognize many features in images so that it can be fine-tuned on a smaller dataset for a new task.
OpenAI’s Contributions in Enhancing Image Recognition Capabilities through GANs
OpenAI, a research laboratory, has made significant contributions to the field of computer vision with the use of generative adversarial networks (GANs). Generative adversarial networks (GANs) are a class of artificial neural networks, that can be used in machine learning and deep learning. Lan Goodfellow and his colleagues are the one who invented this network in the year 2014. It is basically, an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data. The model is trained in such a way that it can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
GANs have been used to develop a variety of computer vision applications, such as image generation, image-to-image translation, and image super-resolution.
The main intent behind the development of GANs is to train two neural networks, known as the generator and the discriminator. OpenAI strategically makes use of these two networks competing against each other in order to generate realistic images. Let’s learn how:
- Generator model: The first network model, known as a generator, creates images based on a given set of parameters. After taking the inputs, it attempts to generate data (images), that are similar to the real data it has been trained on. It learns to create increasingly realistic data as it gets better over time.
- Discriminator model: The second model namely, the discriminator model, evaluates the generated images by the first model. It attempts to distinguish between the real data (images) and fake data generated by the generator. It learns to assign high probabilities to real data and low probabilities to fake data.
FAQs
Convolutional neural networks are one of the most popular kinds of algorithms used in image recognition (CNN). CNNs process images by being passed through layers of convolutional and pooling algorithms that extract progressively more abstract features. k-nearest neighbors, decision trees, and support vector machines (SVMs) are additional image identification algorithms (KNN).
A machine learning model called CLIP (Contrastive Language-Image Pre-Training), created by OpenAI can handle both image recognition and natural language processing jobs at once. CLIP’s performance is based on a sizable dataset of images and the written descriptions that go with them, allowing it to develop the ability to link visual and textual information.
Image recognition has many practical applications in various industries, such as healthcare, manufacturing, retail, transportation, and security. Examples include diagnosing medical conditions from medical images, detecting defects in manufacturing products, analyzing customer behavior in retail settings, identifying objects and obstacles for autonomous vehicles, and detecting suspicious behavior in security footage.
The following are some possible ethical risks that are associated with image recognition:
- Bias and Discrimination: Based on factors like race, gender, and age, image recognition algorithms may be biased against particular categories of individuals. Discrimination and unfair behavior may result from this.
- Misuse: Image recognition software can be used for malicious purposes like tracking down people in risky circumstances or conducting unauthorized surveillance that harm one’s image publically.
- Accuracy and Reliability: When making significant decisions based on the results of an algorithm, the accuracy and reliability of image recognition algorithms can be a worry.
- Misinterpretation: Many times, it may happen that Image recognition algorithms may misinterpret images, leading to incorrect results or outcomes.
Conclusion
Image recognition technology has advanced significantly over time. It has changed the way how we engage with the outside world.
As read above, Image recognition is widely used in various sectors, from security and surveillance to healthcare and retail. With the help of OpenAI’s innovations, such as CLIP, and DALL-E, the field has made significant strides, enabling machines to comprehend and engage with images and text in ways that were previously unthinkable.
Hence, we can say that it will continue to have a profound impact on various industries, and its potential for future innovation is limitless.





